Research @ PLANET AI
Research
Enhancing PLANETBRAIN every day
Enhancing PLANETBRAIN every day
Recent progress in the areas of Artificial Intelligence (AI) and Machine Learning (ML) are tremendous. Almost monthly, we see reports announcing breakthroughs in different technological aspects of AI.
As an organization focussing on research and development, we can look back on an increasing number of awards, publications, and research projects.

Research PARTNERS
Screening all relevant international research, extracting the essence for PLANETBRAIN and at the same time realizing our own ambitious research projects would never be possible without highly qualified and committed partners.
Additionally, we have been co-funded by the European Union for several years.
CITlab and PLANET AI have been joining their research forces for many years and within more than five large research projects aiming to enhance the state-of-the-art technology in the area of Artificial Intelligence and Cognitive Computing.
Joint workshops, monthly CITnet colloquiums, and frequent technology presentations are some examples of our exciting cooperation.









Research Projects
Doctor AI
… is a revolutionary healthcare solution that utilizes advanced AI technology to enhance the accuracy and efficiency of MRI diagnostic scans.
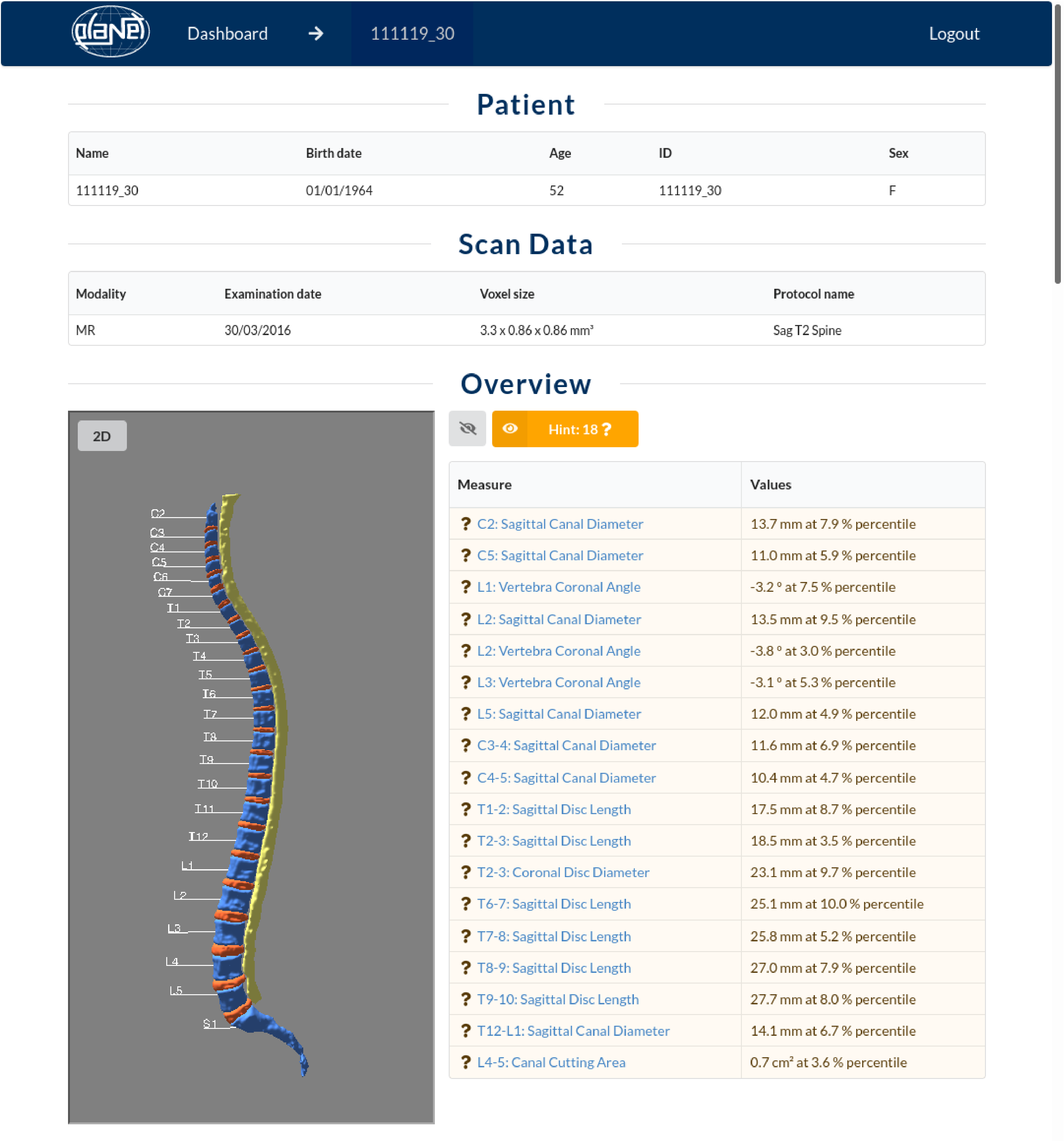
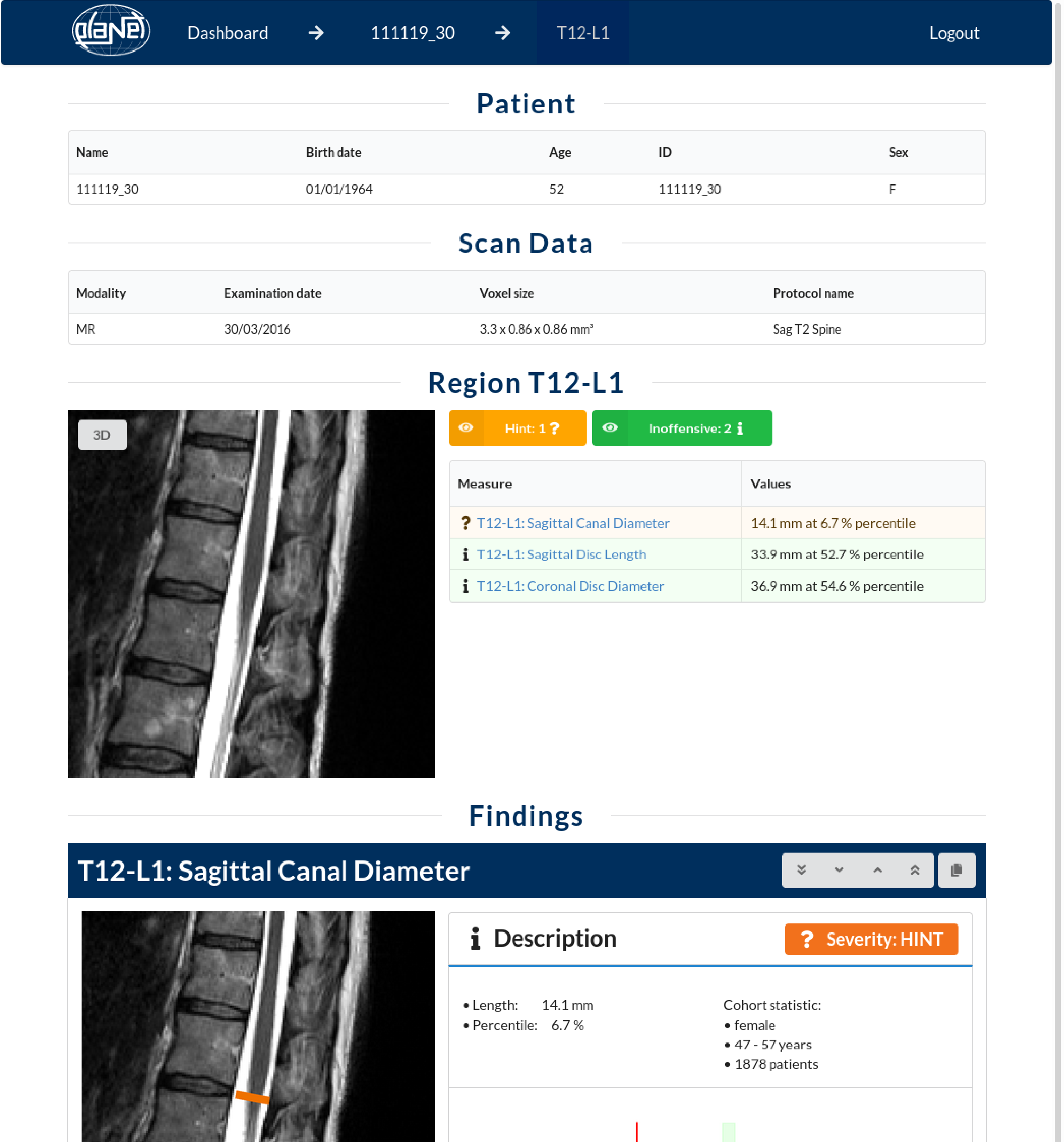
IRA Spine visualizes every single result directly in the sectional image of the MRI scan, displays all measured values and relates them graphically to the reference group.
Deviations are marked by traffic light colors and sorted into the three classes “inoffensive”, “hint” and “warning”.
The visualization in the sense of “Explainable AI” supports physicians not only in diagnostics but also in communication with their patients.
Security Engine
… is a software solution that utilizes AI-powered Object Detection to analyze X-Ray images and enhance threat detection at airports and other secure facilities.

Expanding lists of threats on multiple screens complicate manual baggagge controls at airports or government buildings. Our Security Engine tackles the challenge of monitoring and analyzing large volumes of images. Image Classification determines if there is a threat, whereas Object Detection recognizes the class of threat itself. New categories can be adapted easily, thanks to neural nets.