Forschung @ PLANET AI
Forschung
Wir optimieren PLANETBRAIN Tag für Tag
Wir optimieren PLANETBRAIN Tag für Tag
Die jüngsten Fortschritte auf dem Gebiet der Künstlichen Intelligenz (KI) und Machine Learning (ML) sind enorm und erstaunlich. Fast monatlich sehen wir Berichte, die neue Durchbrüche in verschiedenen technologischen Aspekten ankündigen.
Als Organisation, die sich auf Forschung und Entwicklung konzentriert, können wir auf eine zunehmende Anzahl von Auszeichnungen, Publikationen und Forschungsprojekten zurückblicken.

Forschungspartner
Forschungs-partner
Alle relevanten internationalen Publikationen zu sichten, die Essenz für PLANETBRAIN zu extrahieren und gleichzeitig unsere eigenen ambitionierten Forschungsprojekte zu realisieren wäre ohne diese hochqualifizierten und engagierten Teams nicht möglich.
Zusätzlich werden wir seit einigen Jahren von der Europäischen Union gefördert.
CITlab und PLANET AI bündeln ihre Forschungskräfte seit vielen Jahren und in mehr als fünf großen Forschungsprojekten, die darauf abzielen, den Stand der Technik im Bereich der Künstlichen Intelligenz und des Cognitive Computing zu verbessern.
Gemeinsame Workshops, monatliche CITnet-Kolloquien und regelmäßige Technologiepräsentationen sind einige Beispiele für unsere spannende Zusammenarbeit.









Forschungsprojekte
Forschungs-projekte
Doctor AI
… ist eine revolutionäre Gesundheitslösung, die fortgeschrittene KI-Technologie nutzt, um die Genauigkeit und Effizienz von MRT-Diagnostikuntersuchungen zu verbessern.
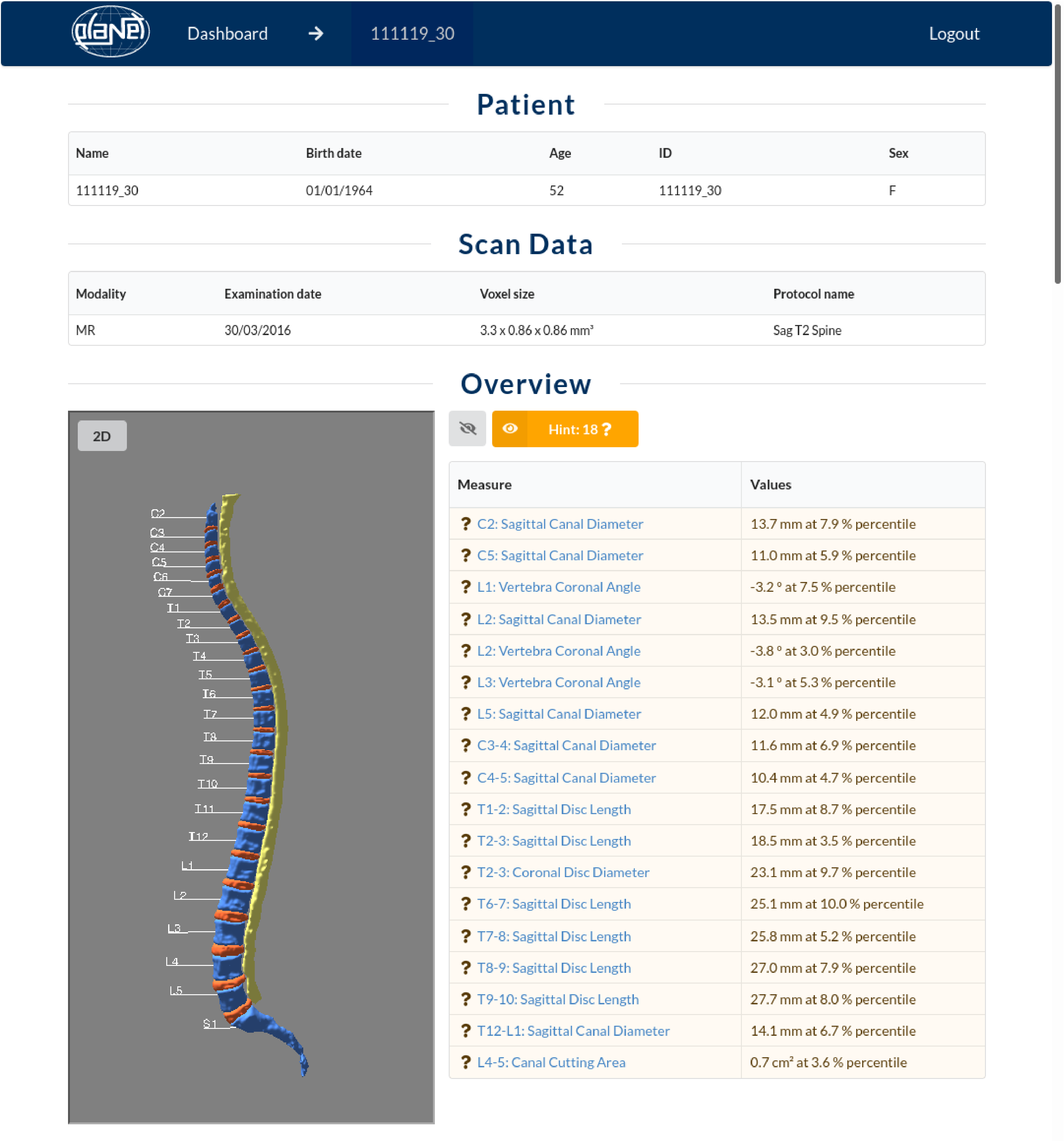
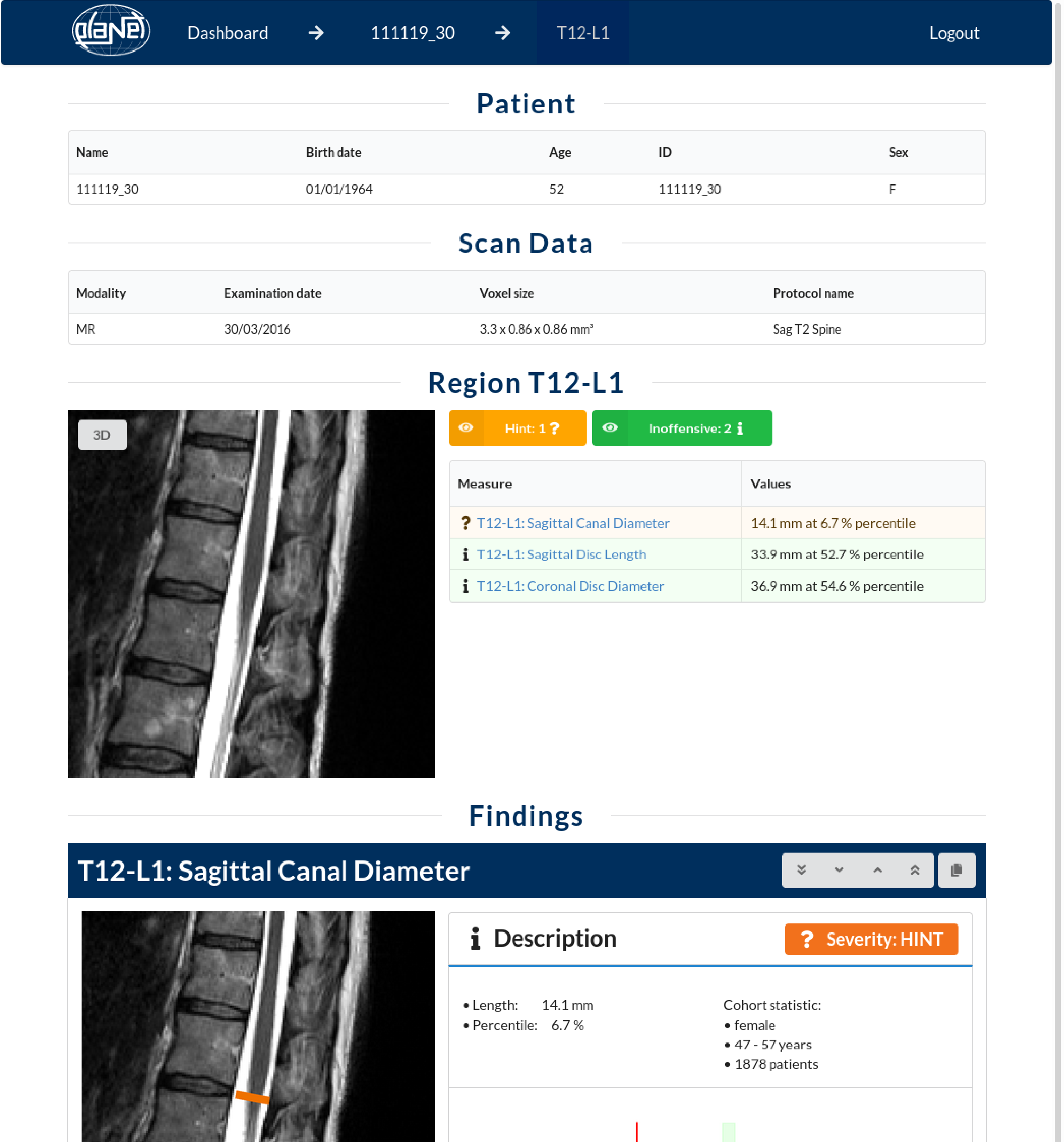
IRA Spine visualisiert jedes einzelne Ergebnis direkt im Schnittbild des MRTs, zeigt alle Messwerte an und setzt sie grafisch in Beziehung zur Referenzkohorte.
Abweichungen werden durch Ampelfarben gekennzeichnet und in die drei Klassen „unbedenklich“, „Hinweis“ und „Warnung“ eingeordnet.
Die Visualisierung als 3D-Modell im Sinne von „Explainable AI“ unterstützt Ärzt:innen nicht nur bei der Diagnostik, sondern auch in der Kommunikation mit Patient:innen.
Security Engine
… ist eine Softwarelösung, die KI-gestützte Objekterkennung verwendet, um Röntgenbilder zu analysieren. Die Software dient dazu, bedrohliche Objekte an Flughäfen und weiteren Einrichtungen zu signalisieren.

Immer umfangreichere Listen von Bedrohungen auf mehreren Bildschirmen erschweren manuelle Gepäckkontrollen an Flughäfen oder in Regierungsgebäuden. Unsere Security Engine meistert die Herausforderung, große Mengen an Bildern zu überwachen und auszuwerten. Die Bildklassifikation bestimmt, ob eine Bedrohung vorliegt, während die Objektdetektion die Klasse der Bedrohung selbst erkennt. Neue Kategorien können dank neuronaler Netze leicht angepasst werden.