IDA Classification
IDA Classification
Based on Machine Learning
Based on Machine Learning

Versatile feature for document categorization tasks
IDA Classification offers exceptional accuracy for challenging document scenarios by analyzing both textual and visual features, even when minimal variation is apparent. Furthermore, it provides a rule-free, few-shot learning approach that dramatically accelerates the setup and maintenance of workflows, in contrast to rule-based or manual approaches.
Performance
Key Features





Explore IDA Classification
Methods
IDA learns and adapts with just a handful of tagged sample documents. It offers versatile classification for single or multi-page files, allowing seamless routing to various downstream processes like data extraction.
Document
Classification

Page
Classification
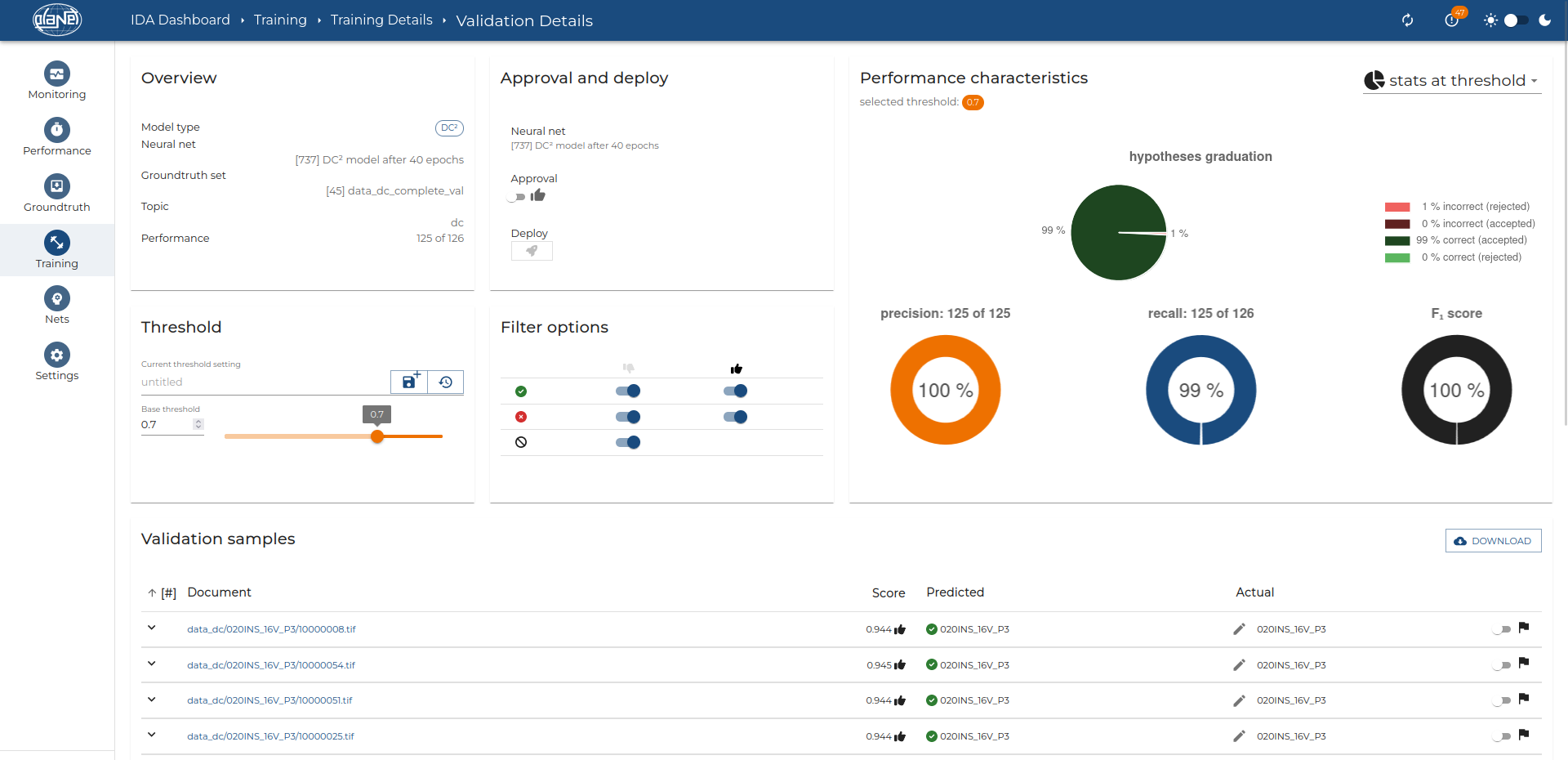
Model Training
User-friendly Interface
IDA provides a user-friendly graphical interface that allows for easy model training without requiring programming experience.
Neural Network
Experience the potential of neural networks for classification. Our approach combines visual and textual features, creating a dynamic model that hones in on vital aspects during training.
For optimum results, start with a minimum of 20 documents per class, or go the extra mile with 100 documents for superior training quality. Even just one blank document per class works for structured layouts.


Bag of Words
Enter a new era of classification with IDA’s rule-based approach and patented PerceptionMatrix technology. Unlike neural networks, IDA is ideal for simpler tasks, focusing on textual features.
It offers a customizable word search within documents, including word groups and sentences. Plus, you can explore the PerceptionMatrix, preserving all transcriptions without losing information.
Add-on
When scanning large batches of documents, it is common to encounter PDF files containing 100 or more consecutive forms. With IDA’s document splitting feature, it is possible to train a neural network to automatically separate document batches containing multi-page documents.

Document Splitting
If your requirements align with past page classifications, harness the efficiency of the same model for document splitting.
Alternatively, take the rule-based route by splitting documents after a fixed number of pages.
For documents with unchanging layouts, a solitary blank form per class is all you need. Remember, for now, document splitting thrives on a neat input order.